Maximum Likelihood Estimation
Let $E$ be the sample space and $\mathbb P_\theta$ be the statical model associated with a sample of i.i.d. r.v. $X_1,..,X_n$. Assume there exists $\theta^*$ s.t. it is the true parameter. Let $A\subset E$ be an interval of events.
Total Variation
The total variation distance between two probability measures, often between our predicted model $\mathbb P_{\hat\theta}$ and the true model $\mathbb P_{\theta^*}$ is
This is saying that the total variation between two probability is the event $A$ that can create the largest difference between these two distributions. For example, if , this is saying $\mathbb P_{\hat\theta}(A)\in[\mathbb P_{\theta^*}(A)\pm 0.1]$, the estimated probability of $A$ will always be off from the true probability by 0.1.
While it is hard to find every subset of the sample space $A\subset E$, there’s an identity whose proof can be found online that can help us. If the sample space $E$ is discrete, then $X$ has a PMF s.t. $\mathbb P_\theta(X=x)=p_\theta(x)$, and
If $E$ is continuous, we have a PDF $P(X\in A)=\displaystyle \int_A p_\theta(x):dx$, and
There’re some properties:
- $TV(\mathbb P,\mathbb Q)=TV(\mathbb Q,\mathbb P)$ (Symmetric)
- $TV\geq 0$ (which can be proved by other properties)
- If $TV(\mathbb P_\theta,\mathbb P_{\theta’})=0$, then $\mathbb P_\theta = \mathbb P_{\theta’}$.
- Triangular inequality
From Total Variation to KL-divergence
Remember our goal is to spit out a $\hat\theta$ that makes our model $\mathbb P_{\hat\theta}$ is as close to the true model as possible. But we do know the so we cannot calculate the nor minimize it. So the strategy is to estimate it, obtaining a $\widehat{TV}(\mathbb P_{\theta},\mathbb P_{\theta^*}),: \forall\theta$. KL divergence is one way to estimate TV. Its formula is (for continuous variable):
It’s a divergence but not a distance. First it’s not symmetric. Although it’s greater than 0 always, it doesn’t satisfy the triangular inequality.
A key property that’s similar to a distance is that
- If $KL(\mathbb P, \mathbb Q)=0$, then $\mathbb P=\mathbb Q$
Ok then how do we approximate this. Note that
Note KL-divergence is not symmetric so need to be careful of the ordering. In general, we use $\mathbb Q$ to estimate $\mathbb P$ and we put $\mathbb Q$ on the righthand side. When we are using $\mathbb P_\theta$ to estimate $\mathbb P_{\theta^*}$, we write , and that will become:
Remember we’re finding the $\theta$ that is closest to , and we can view as an optimal constant. In the $KL(\mathbb P_{\theta^*},\mathbb P_\theta)$, the variable is $\theta$. We view the left half as constants and the right half is the things we minimize to minimize the KL divergence. That is:
which is the maximum likelihood estimation. From line 2 to 3 we’re replacing the expectation with the estimation from the sample, from that on we’re actually getting an estimated KL divergence. In the last line we’re just renaming the product of probability into $\ell$. And emphasize it’s a function of $\theta$.
Convexity
For a function to be strictly convex, it means that its $f’‘>0$ (parabola pointing upward) everywhere not at certain points.This implies that we only have one minima and that will be the absolute one. Similarly if a function is strictly concave, $f’‘<0$ everywhere and it has one maxima. The KL divergence is guarantee to be convex because $KL(\mathbb P, \mathbb Q)=0$ if and only if $\mathbb P=\mathbb Q$. And when we flip a convex function, it becomes a concave one. MLE is a concave function.
For a function $h:\theta\subset\mathbb R^d\rightarrow\mathbb R$ (that would mostly be the likelihood function) that maps a set of parameters to a real number, we generalize the convexity into multivariate. It has
- Gradient vector:
- Hessian matrix:
With these we can check the concavity of the function $h(·)$ by checking the matrix’s definiteness. If the matrix $\nabla^2h(\theta)$ is negative definite, this means the function $h(\theta)$ is strictly concave. And it implies the MLE can find a global maximum (rather than a local one). To test if the Hessian matrix evaluated at $\theta =\hat \theta$ is negative definiteness, we see if $\mathbf x^\top \nabla^2h(\hat \theta)\mathbf x<0,\forall\mathbf x\in\mathbb R^d\backslash {0}$ .
Fisher Information
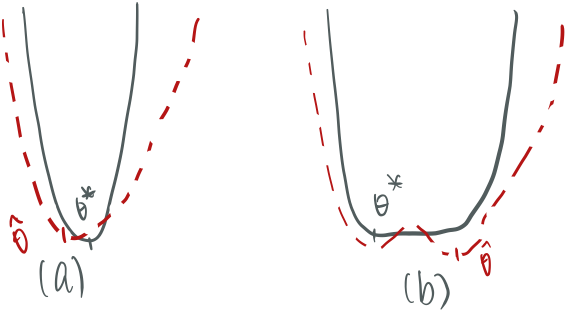
Intuitively, the Fisher information measures how easy a parameter $\theta$ in a model $\mathbb P_\theta$ can be approximated (this is determined by which parameter of a distribution is, like $\mu$ or $\sigma$ in Gaussian, and the value of the parameter). In figure 1, both graphs are KL-divergence graphs (or negative likelihood) w.r.t. a parameter $\theta$. In (a), we see a sharp curve will lead a sharp estimate, this leads the estimated parameter $\hat\theta$ regardless of sample closer to the true one. In (b), when the graph is flatter, it’s harder to get a good estimate to the KL-divergence and thus $\hat\theta$ will likely to far off.
Fisher information is used to measure this. It is the variance of a “score”, the expectation of log likelihood of the data given the model is “true”, that is:
We know the expectation of the score, the variance of a single variable case is just:
When the log likelihood is twice differentiable:
And the expectation of the left term is zero because the $f$ in the denominator is canceled out. And therefore
So Fisher information can be seen as measuring the curvature of the KL divergence. When the curvature is higher, we’re more easily to approximate the parameter.
For instance, the Fisher information for Bernoulli is
In multivariate case, the Fisher Information matrix is just:
the Hessian matrix of log likelihood. An extra tip (with certain assumptions and by central limit theorem) is that $\mathcal I(\theta)$ represents the inverse of variance. When curvature is higher, the variance is smaller (which is a good thing).