Projection Matrices and Least Squares
June 3, 2019
Remember our projection matrix is
Prop. 1 If $\mathbf b$ in column space, $P\mathbf b=\mathbf b$;
Prop. 2 If $\mathbf b$ perpendicular to column space, $P\mathbf b=0$.
Let’s solve Prop. 2 First. What vectors are in perpendicular to the null space of ? From lecture 14, we knew that . One shall easily infer from that . Therefore the vectors in the left nullspace of are perpendicular to its column space. If in , then immediately, and
because we have on the very right.
Coming back to Prop. 1, what is if it is in the column space of ? It’s . Then
is just .

Geometrically, , is also a projection, but it’s just projected into the left nullspace. What’s the projection matrix for ? It is obvious when we expand :
Thus the projection matrix is just .
Least Square
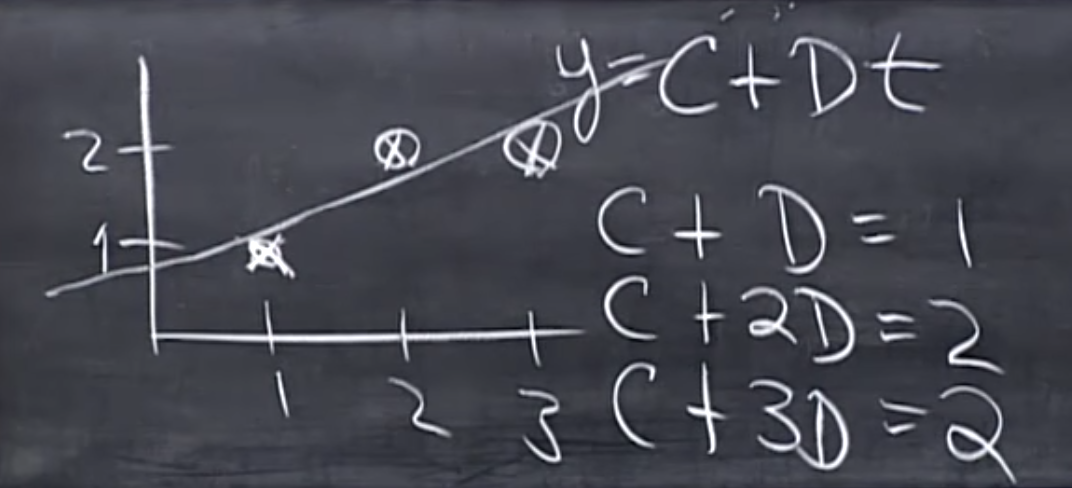
Now let’s turn to linear regression. To put it simple, linear regression is just to find a line that seems to fit a bunch of points well. But you know as long as the points are not in the straight line, we cannot have a line that perfectly goes through every points given. Therefore we need a criterion of what makes a “good” line. Here the criterion is the vertical distance between the line the points projected into the line, which would be clear a bit later.
Let’s do an example. Suppose the points’ coordinates are , we can substitute these points into a line’s equation :
it’s clear that there’s no line can solve these equations since only horizontal line goes through (2,2) and (3,2) but horizontal line does not go through (1,1). Rewrite the equations into matrix form, let , the points x values being and y values being :
Since the equation is unsolvable, the only possible situation is that we solve the solvable ones, where is projected into the column space of X, $C(\mathbf X)$. When is projected into :
For is some random numbers and is just linear combinations of the columns of . Then the error is, similar to before, the unprojected ($\mathbf y$) subtracting the projected,
The error is minimized when $\mathbf p=\mathbf X\boldsymbol{\hat \beta}$ is a vertical projection (refer to note 15 figure 1, p is the vertical projection of b) of . This matches exactly (if you don’t know it’s ok) the square error statistician trying to solve:
Now let’s solve for the that can give us a vertical projection:
is invertible if and only if is full column rank. When it won’t be full column rank? When we have too few points and it has too many columns (i.e. predictor dimension too high). Or we have enough points but some of them are dependent.